


 Рубрики:
Рубрики:  Метки:
Метки: 
Что-то я подумал, почему бы не писать здесь свои мысли, которые (таки да) есть в моей голове — а на самом деле, ниже скопирован мой старый пост от 29 октября 2013 года, и, к сожалению, некоторые картинки ушли в небытие.
Итак… Поисковые системы придумали и делают гениальные ребята. Программисты, лингвисты и еще туева хуча разных мегаспецов. Но прошло всего несколько лет со дня появления по-настоящему умного поиска, и он стал неуправляемым подростком.
В офисе Яндекса фотографам запрещают снимать стены, на которых сотрудники пишут черновики своих поисковых алгоритмов, а за них оптимизаторы готовы продать свою левую почку и правое яичко. Но, кажется, уже никакие формулы не помогут, потому что алгоритмы настолько сложные, что разработчики только по привычке важно раздувают щеки и таинственно вращают глазами, а нифига сами не понимают, как это работает
Простой пример с добрым армянским сайтом, который скопировал статью и из-за ошибки стал лидером поисковой выдачи.
Есть на моем сайте статья о новой модели автомобиля Ferrari. Автор статьи, написанной где-то полгода назад, – ваш покорный слуга.
Вот ее начало:

А вот начало статьи на добром армянском сайте:

Статьи отличаются только тем, что размещены на разных сайтах. И еще тем, что на моем сайте – моя статья и имя фотографа внизу:
![]()
А на армянском сайте – моя скопированная статья без указания моего любимого авторства, без указания имени фотографа, но с офигенно красивым логотипом, который дети Арарата наклепали на каждой чужой фотографии в окружении чужого текста.
Вот девственно чистый кончик их статьи на странице:
![]()
Теперь переходим к делу. То есть, к работе поисковиков Google и Яндекс.
Скопируем начало статьи на армянском сайте и попросим Google найти что-нибудь эдакое…
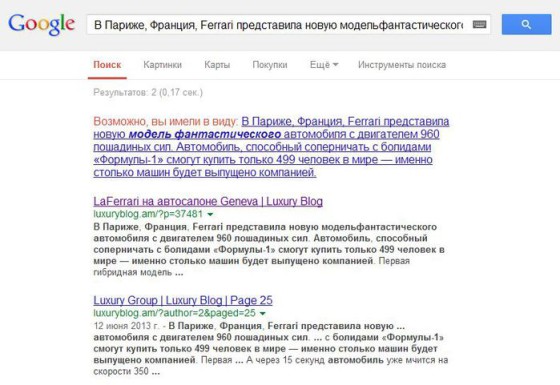
Google думает примерно 1/6 секунды и показывает два результата поиска – добрый армянский сайт.
Теперь скопируем начало статьи на моем сайте (статьи, напоминаю, практически точные копии друг друга). Но Google покажет другую страницу результатов поиска, по-научному – SERP. Здесь вообще нет сайта из Закавказья, а на первом месте – источник статьи:
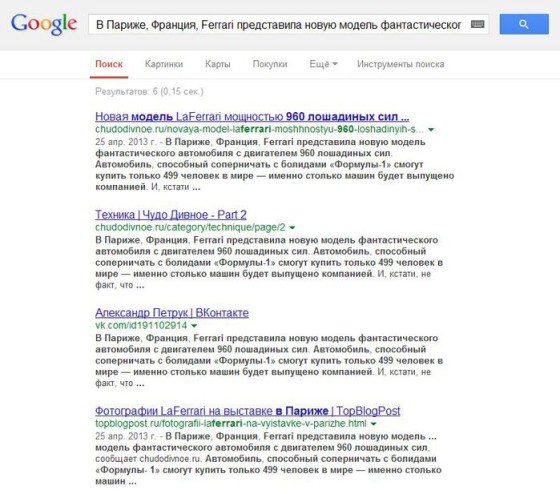
Яндекс тоже делает различия для одинаковых статей сайта-источника и сайта-неисточника.
Вот поиск по тексту скопированной статьи (он первый, оригинал – второй):
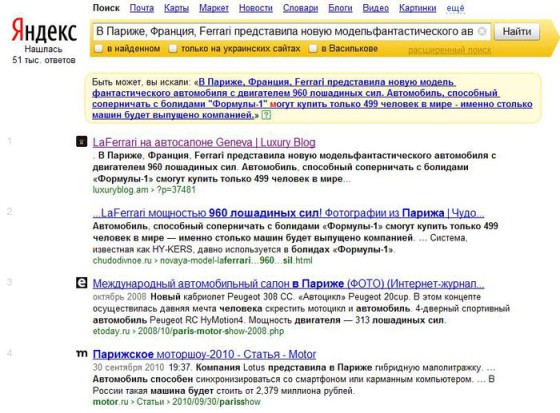
А это – поиск с текстом оригинального сайта (источник на первом месте, копия – на втором):
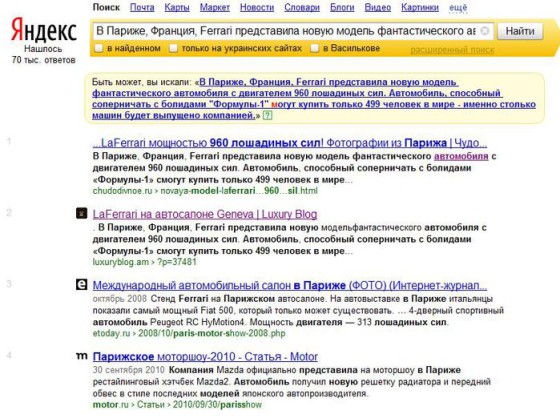
В чем же тайный смысл? А секрет очень прост. Если присмотреться к оригинальному тексту, то в «модель фантастического автомобиля с двигателем» слово «автомобиля» является ссылкой на другую статью моего сайта.
Можно навести курсор на ссылку на сайте армян и на моем – результат будет одинаковый:


В том, что армянский сайт при копировании статьи не заметил ссылку, для меня есть плюс, потому что бесплатная ссылка никогда не помешает. Но при копировании текста со ссылкой пропадает пробел перед словом-ссылкой. То есть у армян написано не «фантастического автомобиля», а «фантастическогоавтомобиля».
И это «новое» интересное слово поисковики считают чуть ли не гениальным достижением писательского искусства и не видят, что тексты – одно и то же.
А разработчики поисковиков сидят в своих калифорниях и раздувают щеки. И да! Вращают глазами еще.
Я считаю, что первое место за ошибку – это отличный повод для урока. Ошибки могут быть полезными, если мы можем извлечь из них выводы и двигаться вперед. Главное – не бояться пробовать новое, даже если это иногда приводит к неудачам.