


 Рубрики:
Рубрики:  Метки:
Метки: 
Обновилась поисковая база Яндекса, предоставив пользователям «зеркало Интернета» за 29-30 октября, и у меня выпало из индекса большинство сайтов.
Просто взяли и выпали. То есть, остались только главные страницы.
В панели веб-мастера во всех сайтах показано, что «Исключено роботом» все страницы со стандартными адресами wordpress, типа, site.ru/?p=111.
Совпадение: эти адреса всегда у меня были запрещены к индексации, но теперь информация о них появилась в панели веб-мастера одновременно с выпадением их дублей с «нормальными» адресами, с ЧПУ.
Начал я писать в техподдержку Яндекса письма с одним вопросом по разным сайтам…
В первом письме привел пример четырех сайтов и получил ответ, что три из них – говносайты. Почему-то про четвертый, который тоже обнулился, в ответе не было ни слова. Дали мне ссылки почитать, что такое качественные сайты.
Подозреваю, что представитель техподдержки, который ответил на первое письмо, просто не разобрался в вопросе, потому что о стандартных адресах и выпавших вместе с ними ЧПУ не было сказано ни слова.
Ответ на второе письмо пришел более конкретный. То есть, просто конкретный: странные дела, дескать, творятся, и ваш «уникальный» случай мы передаем нашим суперспециалистам.
На третье письмо ответа пока нет.
А теперь удивляется другим совпадениям:
1. Напоминаю, что когда робот раздуплился, что адреса /?p= закрыты, то после составления их списка удалил из индекса их близнецов с ЧПУ. Совпадение?
2. На сайтах, где не закрыты от индексации страницы рубрик или меток, удалились из поиска все страницы, кроме… правильно! Кроме рубрик и меток. Ну и, главной страницы. Совпадение?
3. На сайтах, где вообще не было robots.txt, страницы из индекса не выпали. Не выпали и всё тут. Совпадение?
 А по поводу некачественных сайтов… конечно, я люблю свои сайты, но Яндекс имеет полное право на своё мнение по этому поводу. Но еще одно совпадение: ко всем сайтам я отношусь примерно одинаково, создатель всех сайтов и автор статей – один, ваш покорный слуга. То есть, получается, что при прочих равных условиях, качество сайта зависит от того, есть ли на нем файл robots.txt? Других отличий-то нет!
А по поводу некачественных сайтов… конечно, я люблю свои сайты, но Яндекс имеет полное право на своё мнение по этому поводу. Но еще одно совпадение: ко всем сайтам я отношусь примерно одинаково, создатель всех сайтов и автор статей – один, ваш покорный слуга. То есть, получается, что при прочих равных условиях, качество сайта зависит от того, есть ли на нем файл robots.txt? Других отличий-то нет!
Обидно, что назвали говносайтами странички, в которые я вкладывал душу, не говоря о времени и всём остальном. Досадно, что в любом случае, даже если я тысячу раз не виноват и сайты замечательные, в итоге получу только извинение и… сообщение, что вручную никто возвращать страницы в индекс не будет. И появятся они там, в лучшем случае, через несколько месяцев.
А всё из-за чего?
Для тех, кто ничего не понял, резюмирую:
- Сайты все одинаковые.
- Из индекса выпали полностью те, в которых запрещена индексация стандартных адресов wordpress при установленных ЧПУ.
- На «говносайтах», которые лишились всех страниц, остались страницы рубрик, если они были открыты для индексации. То есть – тут говносайт, а тут не говносайт?
- Нисколько не пострадали сайты, в которых не были запрещены к индексации никакие страницы или вообще отсутствовал файл robots.txt.
Казалось бы, при чем тут «наше мнение по поводу качественных сайтов»?..
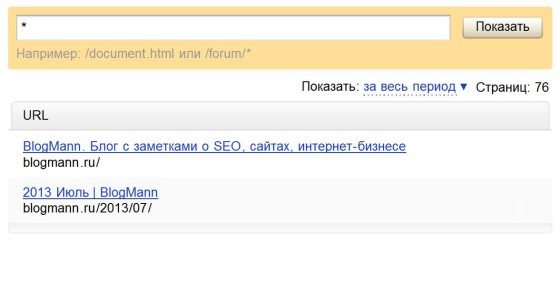
P.S. Кстати, немного об адекватности Яндекса — скриншоты со страницы данных об этом сайте.

Как видно, сообщается, что проиндексировано 76 страниц, а реально показано только две.
Апдейт 9.11. «Яндекс – Капитан Очевидность?»
С грустью прочитал ответ Яндекса на своё письмо. Наверное, так будет всегда – никто не хочет вникнуть проблему. Здесь я даже процитирую, чтобы не быть голословным:
«Ранее индексирование страниц Вашего сайта [сайт] вида [сайт]/?p=136 было запрещено в Вашем файле robots.txt, в связи с чем они не были проиндексированы и не участвуют в поиске… В настоящий момент запрет отсутствует, страницы стали доступны для робота, поэтому по мере его обхода страницы будут проиндексированы. После этого информация в сервисе Яндекс.Вебмастер должна будет обновиться. Подробнее о файле robots.txt…» и так далее.
Интересно, что нового я узнал из этого ответа и ответ ли это на мой вопрос?
Я знаю, что «индексирование страниц Вашего сайта [сайт] вида [сайт]/?p=136 было запрещено». Я знаю, что «в настоящий момент запрет отсутствует» (потому что вообще удалил файл для роботов или удалил строку «disallow */p?*».
Вопрос же был в том, почему запрет был на стандартные адреса, а индексация прекратилась дублей этих страниц с ЧПУ, и все они выпали из индекса.
Наверное, это очень сложно – прочитать вопрос и ответить на него.
Проверила типичные причины: robots.txt и мета-теги (noindex), ответы сервера (5xx/403), некорректные редиректы или rel=canonical, карта сайта в Яндекс.Вебмастере и наличие уведомлений о санкциях. Если все в порядке — отправьте страницы на переобход и посмотрите логи на массовые ошибки; могу помочь пройти проверку шаг за шагом.
— Кристина Шубина
Невероятно, не могу поверить! Все страницы просто исчезли из индекса Яндекса, что же делать? Это полный хаос!